
Best View Synthesis of 3D objects
Published:
We proposed a new novel view synthesis(NVS) model that given a single image input, our model can synthesize images of the same object from arbitrary viewpoints. We extend previous NVS methods by disentangling the learned latent space into content and style sub spaces, s.t. our methods can be used to synthesize texture from realworld images. Experiment results show our method outpreforms classical NVS methods both quantitatively and qualitatively.
Method
The pipeline of our method is shown below.
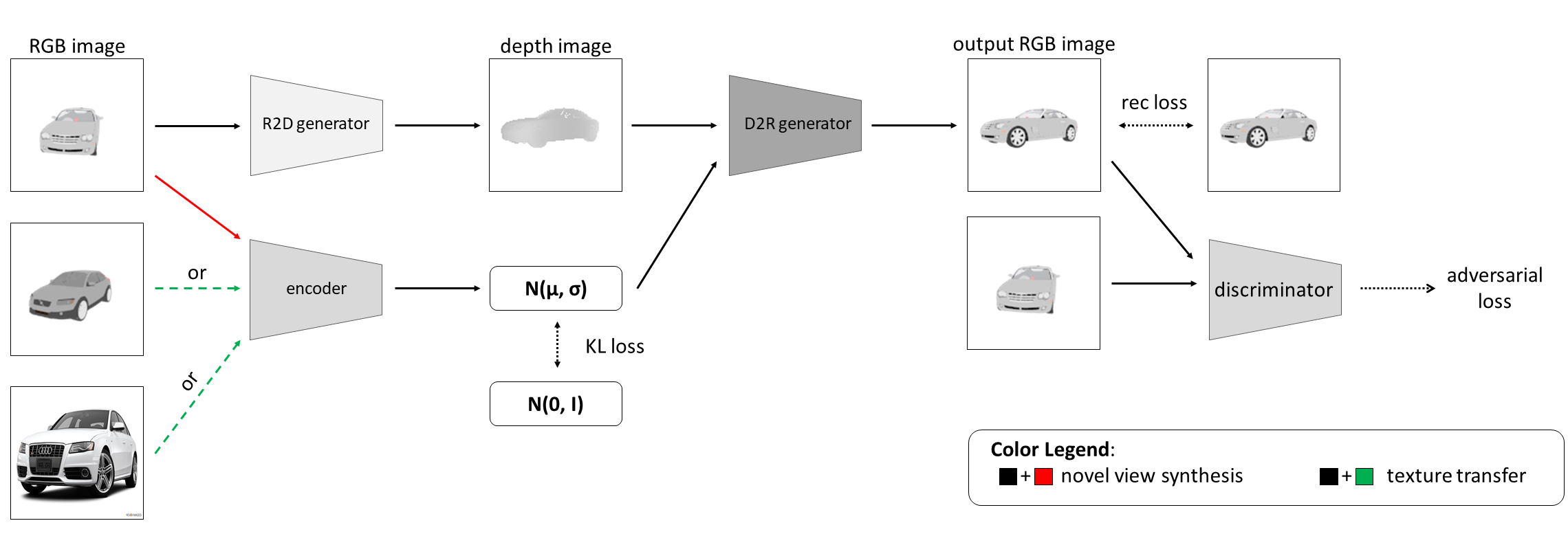
While previous novel view synthesis methods focu on extracting view-independent information from input images, the latent code obtained is in fact disentangled. We believe that by disentangle the latent code into content(represented by depth map) and style(high-dimentional vector) code, the network will be more robust and learn view independent features more efficiently.
We derived a new ELBO in our case, since there are two(not one) latent varibles to be conditioned on. $i$, $c$, $s$ stands for image, content, style respectively.
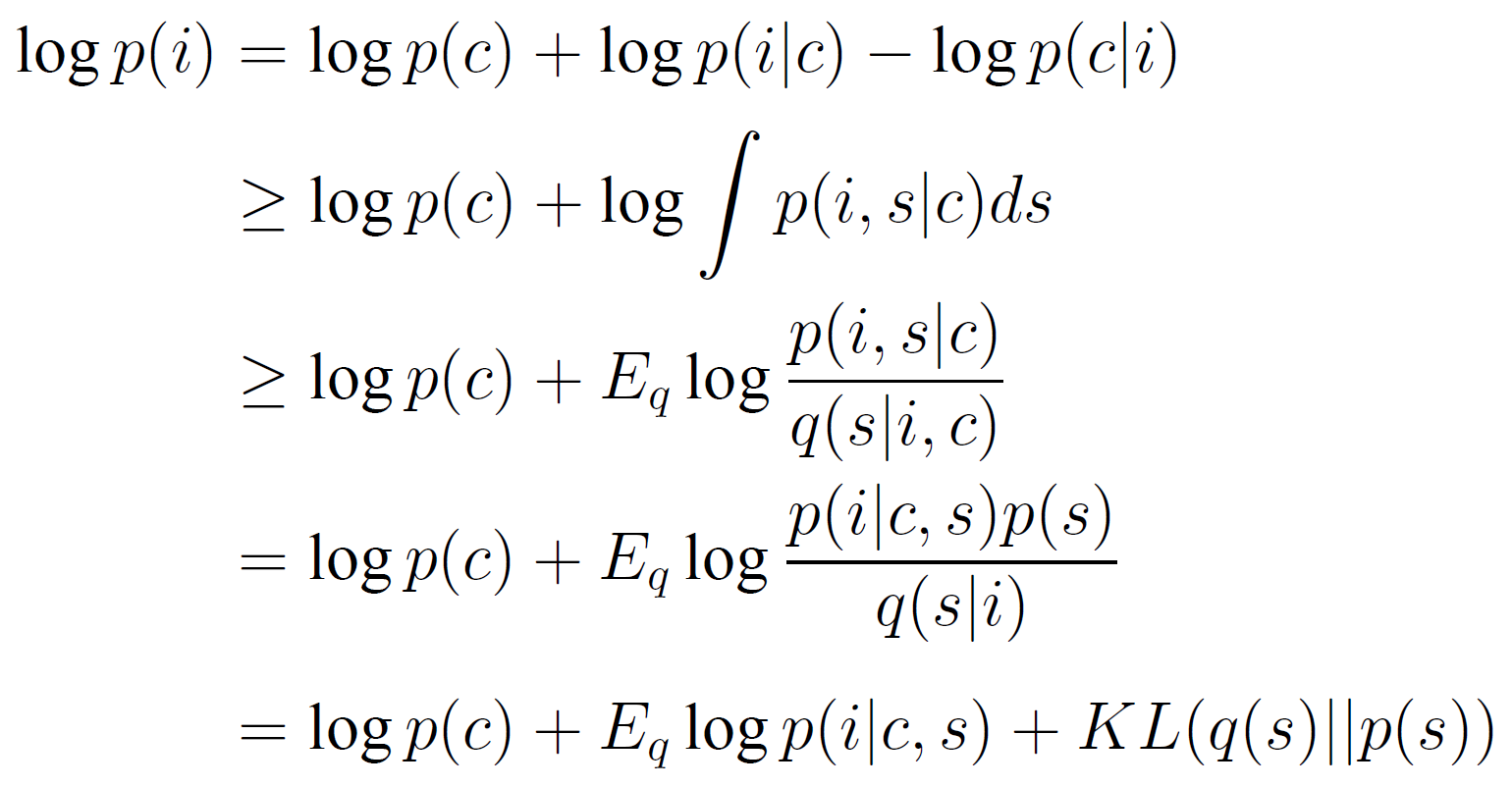
As shown in the above equation, the whole pipeline is trained by minimizing reconstruction loss of both depth image and rgb image and KL loss in latent space. Details about training procedure can be found at Chap. 3-2 (in Chinese).
Results
We show the rotation result and latent code swap result below, more details can be found at Chap. 3-3 (in Chinese).


Applications
Our model can be used to define the best view of 3D model from the intuition that the best view should contain the most texture to reconstruct other views. Also our novel view synthesis network can be used to synthesize 3D models’ texture given a single RGB image(synthesized or from real-world).